
Neural Training
An Adonis ML license is required to use this feature.
The Neural Training Tool is implemented in Houdini as a TOP HDA called AdnMLTraining. This node is a TOPs wrapper around the Adonis neural training script. It provides a Houdini parameter interface to configure and launch the neural training process from a TOP graph.
The tool can be used to train an .adnm model from the input and output data generated by the ML data extraction workflow. It can also use neural cluster data when a neural cluster .json file has been prepared with the AdnNeuralClusteringPaintTool.
The AdnMLTraining TOP HDA can help orchestrate the training process together with other TOP tasks, including data extraction when desired. Connected inputs are not strictly required, but they can be used to define TOP graph dependencies and data flow.
The AdnMLTraining TOP HDA can also help manage the training dependencies. If the required machine learning dependencies are missing when the TOP graph is launched, the tool prompts the user to install them. The dependencies can also be installed manually from Adonis > Utils > Install ML Dependencies.
The training process checks automatically for an available Nvidia GPU and uses that to drastically accelerate training. If a supported GPU device is not available, training falls back to CPU execution, and will be significantly slower. Multi-GPU setups are currently not supported and the training will use the first available device.
This page describes how to run training from Houdini using the AdnMLTraining TOP HDA. For dependency installation options, refer to the Training Dependencies section.
UI
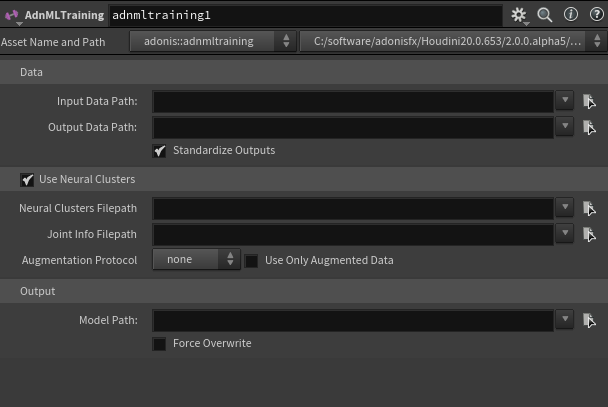
Data
- Input Data Path: Path to the input data
inputs.csvfile exported with Data Extraction. This file is generated by the data extraction process. - Output Data Path: Path to the output data
outputs.csvfile exported with Data Extraction. This file is generated by the data extraction process. - Standardize Outputs: Rescales the output data to a standard normal distribution. This is generally recommended for better training results. If the amount of recorded training poses is low, disabling this option may help improve results for the trained model.
Neural Clusters
- Use Neural Clusters: Enables training with neural cluster data. When enabled, the neural cluster
.json, joint info.json, and augmentation settings are used during training. - Neural Clusters Filepath: Path to the neural cluster
.jsonfile containing the cluster data. This file is generated by the AdnNeuralClusteringPaintTool. - Joint Info Filepath: Path to the joint info
.jsonfile containing the joint information used by the neural cluster training process. This file should be selected from the same dataset folder as the input and output data files generated during data extraction. - Augmentation Protocol: Experimental data augmentation protocol to apply during training. Use only when training without augmentation is not giving good results and the dataset is small. Available options are none, random, and simple. This option uses the neural clusters to generate new synthetic pose data from the training samples. The random protocol generates new synthetic pose data by composing isolated deformed neural clusters with a random sample pose deformation from the dataset. The simple protocol generates new synthetic pose data by composing isolated deformed neural clusters with the rest pose, index
0dataset sample, deformation. The synthetic poses generated may contain artifacts and may be less aligned to the original simulated silhouette. - Use Only Augmented Data: Uses only the augmented synthetic data for training, without including the original samples. This option is ignored if no augmentation protocol is selected.
Output
- Model Path: Path where the trained model file will be saved. The output file must use the
.adnmextension. - Force Overwrite: Forces the tool to overwrite the model file if it already exists in the target path. Use with caution, because this will irreversibly delete any existing model file at the target path.
Requirements
To train a model with the AdnMLTraining TOP HDA, the following files are required:
- Input Data Path: Input data
inputs.csvfile exported with Data Extraction. - Output Data Path: Output data
outputs.csvfile exported with Data Extraction. - Model Path: Output
.adnmmodel path.
The input and output data files are generated by the data extraction workflow. For more information about generating training data, refer to the AdnMLDataExtraction TOP HDA documentation.
The output model path must use the .adnm extension.
When training with neural clusters, the following additional files are required:
- Neural Clusters Filepath: Neural cluster
.jsonfile generated by the AdnNeuralClusteringPaintTool. - Joint Info Filepath: Joint information
.jsonfile used by the neural cluster training process. This file should be selected from the same dataset folder as the input and output data files generated during data extraction.
The AdnMLTraining TOP HDA does not strictly require connected inputs. Inputs can be used to define TOP graph dependencies and data flow, but the training files are selected through the path parameters.
How To Use
-
Create a TOP Network node in Houdini, or enter an existing TOP context where the training process will be configured.
The same TOP network used for data extraction can also be used for training, or a new TOP network can be created only for the training step.
-
Create an AdnMLTraining TOP HDA in the TOP graph.
The AdnMLTraining TOP HDA can be used as part of a TOP graph to orchestrate the training process.
Connecting inputs is optional. Inputs can be used to define graph dependencies and data flow, but the files used for training are selected with the path parameters on the node.
-
Set the input and output data paths.
Use Input Data Path to specify the input data
inputs.csvfile exported with Data Extraction.Use Output Data Path to specify the output data
outputs.csvfile exported with Data Extraction.These files are generated by the data extraction process. For more information about generating training data, refer to the AdnMLDataExtraction TOP HDA documentation.
Enable Standardize Outputs to rescale the output data to a standard normal distribution. This is generally recommended for better training results. If the amount of recorded training poses is low, disabling this option may help improve results for the trained model.
-
Enable neural clusters if needed.
Enable Use Neural Clusters to train using neural cluster data.
When this option is enabled, the training process uses the neural cluster
.jsonfile and the joint info.jsonfile for optimizing the network architecture.Use Neural Clusters Filepath to specify the neural cluster
.jsonfile containing the cluster data. This file is generated by the AdnNeuralClusteringPaintTool and describes the painted cluster regions used to provide locality information during training.Use Joint Info Filepath to specify the joint info
.jsonfile containing the joint information used by the neural cluster training process. This file should be selected from the same dataset folder as the input and output data files generated during data extraction. -
Configure augmentation if needed.
Use Augmentation Protocol to apply an experimental data augmentation protocol during training.
Use this only when training without augmentation is not giving good results and the dataset is small.
The available augmentation protocols are none, random, and simple. When augmentation is enabled, the tool uses the neural clusters to generate new synthetic pose data from the training samples.
- random protocol will generate new synthetic pose data by composing isolated deformed neural clusters with a random sample pose deformation from the dataset.
- simple protocol will generate new synthetic pose data by composing isolated deformed neural clusters with the rest pose, index
0dataset sample, deformation.
These generated poses may contain artifacts and may be less aligned to the original simulated silhouette. The use of this option will increase the hardware memory requirements during training.
Enable Use Only Augmented Data to train only with the augmented synthetic data, without including the original samples.
Use Only Augmented Data is ignored when Augmentation Protocol is set to none.
-
Set the output model path.
Use Model Path to specify where the trained model file will be saved.
The output model path must use the
.adnmextension.Enable Force Overwrite to overwrite the existing model file if one already exists at the target path. Use this with caution, because the previous model file will be irreversibly deleted.
-
Cook the TOP graph.
Cook the TOP graph to launch the training work item.
Use the TOP execution buttons to generate static work items and cook the graph, similarly to the data extraction workflow.

-
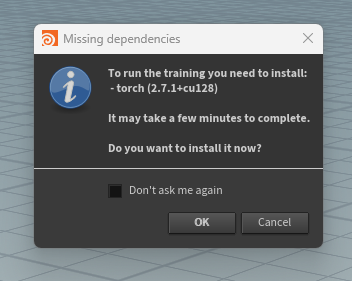
Install missing dependencies if prompted.
If the required machine learning dependencies are missing, the tool displays a prompt when the TOP graph is executed.
Press OK to install the dependencies from the prompt. This may take a few minutes.
-
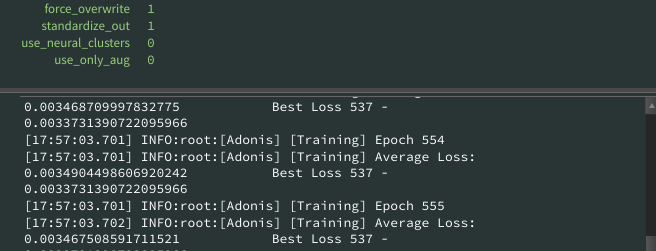
Review the training output.
After training finishes, the
.adnmmodel file is written to the Model Path.The tool also generates a
<model_name>_log.txtfile next to the.adnmmodel. This log can be used to inspect training progress, epochs, losses, warnings, and errors.A
<model_name>_config.jsonfile is also generated with the training parameters used for the run. This can be used to review how the model was trained.During or after execution, the work item output can also show epoch and average loss information. This is useful for debugging training behavior directly from TOPs.
Training Dependencies
The AdnMLTraining TOP HDA requires the machine learning dependencies to be installed before training can run. For more information about the ML dependencies installation, please refer to this section on the Installation page.
- The training process checks automatically for an available Nvidia GPU and uses that to drastically accelerate training. If a supported GPU device is not available, training falls back to CPU execution, and will be significantly slower. Multi-GPU setups are currently not supported and the training will use the first available device.
- Machine learning dependencies are installed inside the Adonis installation directory rather than system-wide. As a result, the system environment remains unchanged and no global Python packages are installed.
Output Files
After a successful training run, the following files are generated:
<model_name>.adnm: Trained Adonis neural model file.<model_name>_log.txt: Training log file generated next to the.adnmmodel.<model_name>_config.json: Configuration file storing the training parameters used for the run.
The <model_name>_log.txt file can be used to inspect the training process. It contains epoch information, average loss, best loss, warnings, errors, and other training messages.
The <model_name>_config.json file can be used to review the training configuration used to produce the model.
Recommendations
- Use data generated by the AdnMLDataExtraction workflow as the training input and output data.
- Keep the input data, output data, and joint info files together in the same dataset folder.
- Use Standardize Outputs for most training runs.
- Consider disabling Standardize Outputs only when the number of training poses is low and preserving the original output distribution gives better results.
- Use neural clusters when local deformation regions should be isolated during training.
- Use augmentation only when the dataset is small and training without augmentation is not producing good results. However, if possible, recording new data should always be considered first.
- Prefer GPU training when compatible hardware and dependencies are available, because it is usually faster than CPU training.
- Review the generated
<model_name>_log.txtfile after training to inspect epoch progress and loss values. - Review the generated
<model_name>_config.jsonfile to confirm the training configuration used for the model. - Avoid neural clusters with large and redundant overlapping regions, because they can reduce training quality.
- Very small datasets may produce lower-quality models, especially when training complex deformations.
- Use Force Overwrite carefully, because it deletes any existing model file at the target path.
Troubleshooting
If the training process fails or does not produce the expected result, check the following:
-
Check the TOP work item task graph and output.
The TOP task graph can show whether the work item failed and may provide error information for the failed task. The work item output can also show epoch progress, average loss, and best loss information, which is useful for debugging training behavior.
-
Check the generated
<model_name>_log.txtfile.The log file is generated next to the
.adnmmodel and contains detailed training information, including epochs, losses, warnings, and errors. -
Check the generated
<model_name>_config.jsonfile.The config file records the training parameters used for the run. This can help confirm that the correct paths, neural cluster settings, augmentation settings, and output options were used.
-
Confirm that the ML dependencies are installed.
If the dependencies are missing, install them from the prompt or from Adonis > Utils > Install ML Dependencies.
-
Confirm that the output path is valid.
The Model Path must use the
.adnmextension. If a model already exists at the target path, enable Force Overwrite only if the existing model can be safely replaced. -
Confirm that the learning was successful.
The training process will automatically stop when the predicted outputs stop improving. If the log shows training stopped after a small number of epochs, for example fewer than
100, try recording new data or adjusting the cluster definitions. Datasets that are too small or clusters with too many overlapping regions can be detrimental for learning.
Limitations
- Multi-GPU setups are currently not supported and the training will use the first available device.

